A couple weeks ago, I saw the following image in my Twitter feed:
I, for one, am old enough to have lived through all 3 of these paradigms for software architecture. The team on which I am a part has been strategically tasked largely with taking a spaghetti codebase and moving to ravioli. So the analogy fits (though in retweeting this pic, I did claim to be a bit more of a tortellini fan myself.)
That said, what is not illustrated in this infographic is the complexity associated with each form. Arguably, spaghetti is easier, mostly because you can avoid caring about things.
Attention to architecture creates a burden that developers must appreciate in order to deliver.
Case in point: If I don’t care about architecture, I can create a single web page that connects directly to my database from the server-side code-behind. This was not unusual in the spaghetti days. Every page opening its own database connection. Defining its own objects (that is, unless you just use the DataRow.) In the spaghetti days, there was no Pragmatic principle of Don’t Repeat Yourself. We were proud of ourselves for making it work, and moved on to the next strand.
Today, our system has the following flow to query a database:
Client UI Page -> Controller -> API Wrapper -> API -> Provider -> DataStore -> ORM -> Database
Now we have a Visual Studio solution containing 10 or 12 assembly projects to accomplish the same thing we used to do in a single page. We transform a database record to an entity, then to a Data Transfer Object, then to a Query result, then to a json object, then to a result object, then to a model.
Because now we care. We’ve learned to care over the last 3 decades because there is inherent value in the architectures when it comes to code reuse, reliability, and testability. But now, ravioli making takes time.
In my own journey towards ravioli, I’m learning to appreciate the steps. The beauty of component parts, each tasked with a single purpose, able to live in their own cozy pocket of dough. But the cost of that coziness is time, fore-though and planning. It’s an investment, and reminds us that software, like artisan pasta making, is a craft.
Earlier this month, I wrote about how it’s inevitable that you’re going to be distracted during the course of your workday. Today I’m adding a second installation to the “You’re going to…” series by assuring you that You’re going to fall behind.
What I mean by this is that as a developer, there will always be things you can’t keep up on. Be that a new language, framework, toolkit, backlog of features, unit test coverage, or even documentation. There simply has become too much to learn, too much to consume, too much to monitor, for any normal person with a day job to manage. And that is okay.
Back in the day
When I started software development in the late 1990’s, there really were fewer options for how you did your work. It really came down to a few languages, and those mostly supported by Microsoft, namely FoxPro, Visual Basic, and C++. Even Java, released in 1995, was only beginning to garner some momentum. Consequently, there were finite choices, and seemingly finite amounts of reference material to consume. These are the days when not only would you get 25 3.5 inch floppy disks to install the product, you’d get 3 or 4 printed volumes as instructional guides. If you were lucky enough, as I was, to have an employer who would spring for the CD-ROM based MSDN library subscription, then your reference base grew a bit more, especially with each quarterly release.
But in the end, if I had a problem I couldn’t solve, the standard solution was at the other end of the Microsoft Support telephone number. I have many memories of sitting on hold waiting for a support representative to pick up so I could ask a single question.
The release cycles for new products in the late 90’s and early 2000’s were long. And the infancy of the Internet at that stage meant that only so many new products or technologies became available each year. I dare say it was manageable, and if you paid attention, you could reasonably stay current with the latest and greatest.
The Internet changed everything
In my view, the Internet has had two significant impacts on the field of software development. The first is the amount of content available related to any given programming language, or in fact any given specific issue. The second is the acceleration of new technology being released for developers to leverage.
To illustrate the former point, do a simple Google search for your programming language of choice. The results may surprise you.
21 million results. 21 million pages that all may have something relevant to the problem you are trying to solve. It’s no wonder we feel overwhelmed.
How to keep up
Just as you would if you found yourself falling behind the pack in a footrace, keeping up with the industry requires that you dig deep in to your core and put all you have towards closing the gap. Here are some things I have found useful.
1. Plan to give a talk
One of the most effective ways I have found to embark on learning a new technology or method is to commit myself to giving a presentation about that topic. This can be at a user group, a code camp, or even just as a lunch-and-learn with your team. The risk of embarrassment in front of your peers is a giant motivator, and a deadline can help you prioritize and structure your learning.
2. Optimize your online consumption
With the glut of material out on the Internet, how possibly do you filter though the volume and get to the best resources. One method I use is to always start with what I call my trusted sources. These are individuals like Scott Hanselman, K. Scott Allen, and Randy Drisgill, who have an established reputation as reliable authors. The next tier is material from the producers of the technology themselves. Everything from Microsoft down to the discussion threads on CodePlex, if it’s directly tied to the people creating the technology, chances are you’ll get better quality information. Finally, expand to the general tech blogosphere. Every developer has their own application and experience with a language or tool, and that broad base will give you lots of insight as to what is good, bad, and ugly about the product.
3. Online video and Podcasts
In the last few years there has been a downright explosion of online video training materials available online. Free sites like DimeCasts; paid sites like WintellectNow and Pluralsight; and of course, lots of user-sourced material on YouTube. The genre of tech-focused online screencasts is maturing rapidly and gaining not just popularity, but quality. Similarly, chances are there are dozens of individual podcasts available oriented around the topic du jour. Online training and podcasts are great because they can be portable as well as passive. You can listen to a podcast while on the treadmill, or watch a video while traveling. These are great tools to help you incrementally grow in knowledge.
4. Start a side project
If you are like me, and I think most developers, you learn best by doing. So if your main job doesn’t afford you the opportunity to explore and apply new technology, create your own project that does. I started HomeSpotHQ.com in 2009, and it became the venue in which I learned MVC. Setting off to create a product, whether or not you make it public, is a great form of focused learning. If you’re particularly motivated, you can follow in Jennifer Dewalt’s footsteps and do 180 websites in 180 days, each implementing a specific method or tool. The point is to not just read and watch, but do.
Long journey, first steps
I think being a developer forces you to be a lifelong learner. There’s no other way to stay competitive and relevant in the marketplace. So when you find yourself worrying or frustrated because you learn about yet another JavaScript framework that released, remember that we’re all in the same boat. Pick up an oar, set a target, and get to work.
I must be in a bit of a ranting mode this week, but I couldn’t get past this one.
So I’m implementing a web based calendar for a client. I decide to use a fairly normal jQuery plugin called FullCalendar. For the most part, it works as you’d expect.
Query a list of events. Render a calendar, with those events displayed.
My client’s requirement stated that when the calendar loads, show the current month. But every time it loads, we actually were showing the next month into the future. March became April.
Tracing, breakpoints, quickwatches. All the date values look correct. But the default month never matched the current month.
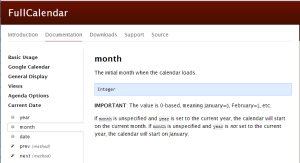
Then I figured I would RTFM and to my amazement, I found this:
IMPORTANT: The value is 0 based, meaning January=0, February=1, etc.
However, the year parameter is not zero-based, meaning 2013 == 2013.
If I had to guess, the month value might be handled in an array. And most arrays are zero-based. Fine. But when you alter the basic expectation of what a value is and how it behaves, you fail your user. You waste their time. You’ve wasted my time and my client’s money.
Writing code that is consumed by others requires that you think about the consumer and making their life easier, not take shortcuts to make your life easier.
At least I can appreciate that this peculiarity was included in the otherwise admirable documentation. And I definitely appreciate the overall functionality of this plugin. But I don’t appreciate creating an exception when one doesn’t need to. It smells of laziness, and as coders we can do better.
Perhaps not the most debated topic among developers, but one that is certainly on the list, is how, when and why to put comments in to code.
One side argues that leaving comments and clues is a reasonable courtesy for the poor sap who inherits your code after you are long gone.
The other side claims their code is so beautifully written and self-explanatory that no annotations are required.
In my daily work, there are four places where commentary is possible:
In the code itself
On source control commits
On bug reports or user stories
On invoice time records
All of these contexts have different levels of necessary comments, and different purposes (and consequences) tied to those comments.
Inline comments
By far the most common form of inline comment I use is to reference a bug ticket. Whatever bug tracking or work item system you use, it probably assigns a nice integer to each item. So when you fix that bug, you can notate the bug that is behind the change.
//24549 send manual refund email if needed
if (manualRefunds.Count > 0)
SendManualRefundEmail(currentStudentTestEvent, manualRefunds);
These comments make it trivial to find all the changes associated with a bug fix, simply by doing a search for the bug id.
Another rule for inline comments is when, for whatever brilliant reason, a non-intuitive decision is made and implemented in code. These comments are what make your code ‘senile-proof’. What I mean by that is that we should just admit we can’t remember everything, and whether for our own sake or for the sake of our team, we need to record what we were thinking when we coded that magic number or unusual sequence. Other times, we just point out the obvious.
//2011-01-11:DMS - retrieve event to get test method
Model.OpenTestEventSearch openTestEventSearch = TestEventBL.GetOpenTestEventSearch(studentTestEvent.TestEventID)
.Where(o => o.TestGradeID == studentTestEvent.TestGradeID)
.FirstOrDefault();
Source Code Commits
Checking code back in to the repository is a historic event. In doing so, your code (working or not) is forever committed. Just like any other monument, it’s nice to put a little plaque up to commemorate the event.
In most cases, a commit will follow a bug fix, in which case your commit comments should also include the bug ID and a brief description of the fix.
In other cases, you did something else, such as adding comments (!) or merged a code branch. In those cases, a brief note about the change will help others on the team know why in the world you committed.
Bug ticket closure
In many (all?) bug tracking systems, when a case is resolved, the user has the opportunity to submit an update to the case. Again, these notes can be concise, and can reference back to the revision or changeset in source control in which the code changes occurred to clear the case. The level of detail required depends a lot on the other users of the bug tracking tool. If end users will get updated upon the case closing, and they want an explanation of the fix, then you should give it to them. However, if only project managers see it, and they are satisfied with a simple note saying “fixed in DEV branch”, then by all means, save the keystrokes.
Time entries
As a consultant, everything I do is tied to a time entry that ultimately ends up on an invoice to a client. Therefore, when comments are put on time entries, they need to be ‘client friendly’. In our case, however, the time entry is associated to a bug or work item, which has already been annotated, so the level of detail required is slightly less on the invoice.
As all developers do, when we inherit someone else’s code, we are thankful for the information left for us by our predecessors. It’s only reasonable to return the favor for those who come after us.
What are your rules for commenting? Add your thoughts below.
If you have ever inherited somebody else handiwork and the code therein, you’ll appreciate what Robert C. Martin has to say in this keynote speech at the QCon London 2010 conference earlier this year. It is well worth the hour.